Aqua Analytics
Aqua-Analytics: A Data-Driven Insight into India's Drinking Water Accessibility - From Coverage Metrics to Implementation Integrity.
Preview Gallery
6 media

Technologies & Skills
Limited time offer
What's Included
Support & Customization
Resource Links
Purchase this project to unlock source and premium resources. Document/report remain secure preview-based on this page.
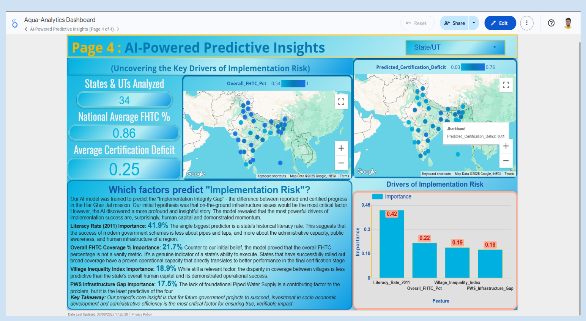
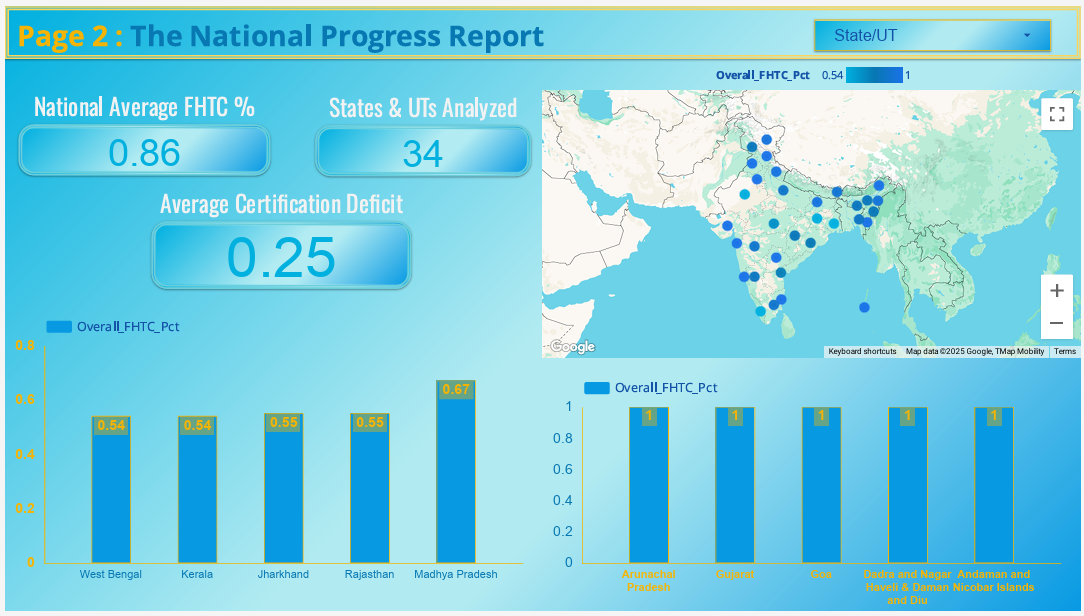
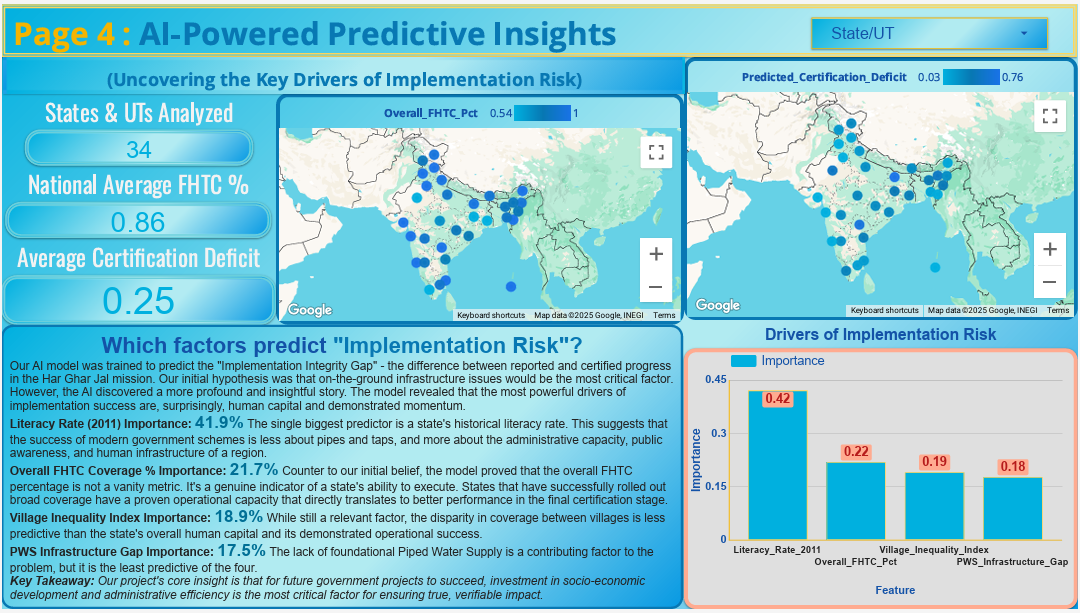
Access to safe drinking water is a cornerstone of public health and economic stability in India. While national initiatives like the "Har Ghar Jal" mission have made monumental strides in expanding tap water coverage, a new, more complex challenge has emerged : ensuring the long-term integrity and verifiable success of this massive undertaking. Official reports may show high coverage percentages, but these numbers can often mask deep-seated issues. There is a critical gap between progress that is reported by local bodies and progress that is officially certified as complete and functional. This "Certification Deficit" represents a significant risk, indicating potential problems in data quality, last-mile execution, or administrative hurdles. Without a system to proactively identify and understand the drivers of this gap, resources cannot be targeted effectively, and the true impact of the mission remains opaque, putting the long-term sustainability of the investment at risk.
Our solution, Aqua-Analytics, is an AI-powered platform designed to shift the focus from simple coverage metrics to a deeper analysis of implementation integrity. It provides a multi-layered insight into India's water accessibility challenge.
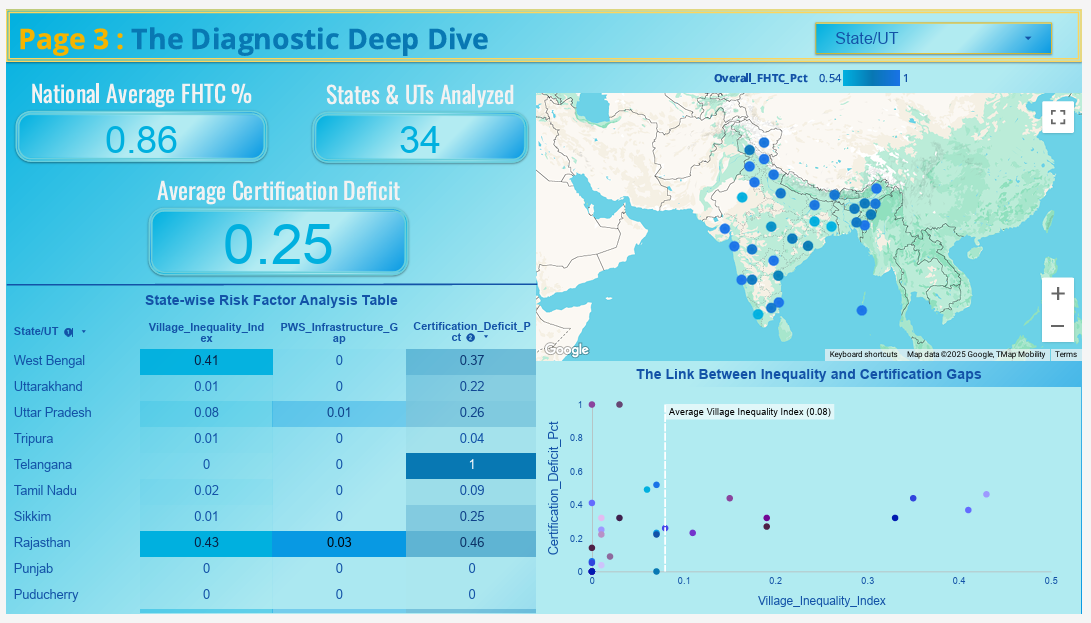
1. Diagnostic Analysis: We first aggregate and analyze multiple public datasets to create a comprehensive, state-level view of the current situation. This includes not just overall coverage, but also our own uniquely engineered metrics like a Village Inequality Index and a PWS Infrastructure Gap.
2. Predictive AI: The core of our innovation is an AI model that predicts a state's risk of developing a high "Certification Deficit." By analyzing the relationship between foundational infrastructure, socio-economic factors, and on-the-ground inequality, our model uncovers the hidden drivers of implementation challenges, allowing for proactive, data-driven interventions.
Future Enhancements
Known Issues
Installation
To set up this project locally, please follow these steps:
- Clone the repository from GitHub using
https://github.com/dev-sayantan/skillbolt_ideathon_project.git
- Verify Python Environment: Ensure you have Python 3.8 or higher installed on your system.
- Install Dependencies: Open your terminal or command prompt and run
pip install -r requirements.txtto install necessary libraries like Pandas, NumPy, and Scikit-learn. - Launch: Open the project folder in VS Code or launch Jupyter Notebook to begin your analysis.
Usage
After completing the installation, you can interact with the project through the following workflow:
- Data Input: Place your source dataset (CSV or Excel format) into the
/datadirectory. - Execute Analysis: Run the primary script or Jupyter Notebook cells sequentially to perform data cleaning and exploratory analysis.
- Generate Visualizations: The project will automatically generate interactive charts or Power BI-ready reports based on the processed data.
- Review Outputs: Final predictive insights and statistical summaries will be displayed in the output console or saved as a PDF report.
System Requirements
For optimal performance and to ensure all dependencies run correctly, the following specifications are recommended:
- Operating System: Windows 10/11, macOS, or a stable Linux distribution.
- Software/Runtime: Python 3.8+, Microsoft Excel, and Power BI Desktop (for visualization components).
- Memory (RAM): Minimum 8 GB (16 GB recommended for handling large clinical or biological datasets).
- Disk Space: At least 500 MB of free space for project files and local data storage.
Slides Open in New Tab
For better readability, slides are opened directly. Documents remain preview-only with secure backend rendering.
Showing preview pages only. Purchase for full access to all pages and complete source package.
Login for Full AccessNo Q&A available yet
Be the first to ask a question!
Ask a Question
Customer Reviews
Write Your Review
No reviews yet
Be the first to review this project!